Statistical analysis of a fracture network#
This notebook will show how to perform statistical analysis of the analyized network by:
Fit different distributions to the dataset
Plot summary plots for each fitted distribution
Visually compare different fits using PIT
Show and export statistical summary tables
[1]:
from fracability.examples import data # import the path of the sample data
from fracability import Entities, Statistics # import the Entities class
import scipy.stats as ss
import matplotlib.pyplot as plt
Import the Pontrelli quarry Set a and calculate the topology#
[2]:
pontrelli_data = data.Pontrelli()
data_dict = pontrelli_data.data_dict # Get dict of paths for the data
# Create the fractures and boundary objects.
set_a = Entities.Fractures(shp=data_dict['Set_a.shp'], set_n=1) # to add your data put the absolute path of the shp file
boundary = Entities.Boundary(shp=data_dict['Interpretation_boundary.shp'], group_n=1)
fracture_net = Entities.FractureNetwork()
fracture_net.add_fractures(set_a)
fracture_net.add_boundaries(boundary)
fracture_net.calculate_topology()
Calculating intersections on fracture: 1945/1945
[3]:
fracture_net.fractures.entity_df
[3]:
| id | Fault | Set | dir | geometry | original_line_id | type | censored | f_set | length | b_group | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | None | 1.0 | 1.0 | 123.16300 | LINESTRING (636960.853 4518526.132, 636960.853... | 1 | fracture | 1 | 1 | 4.8394 | -9999 |
| 1 | None | 1.0 | 1.0 | 123.73829 | LINESTRING (636964.885 4518523.498, 636964.905... | 2 | fracture | 0 | 1 | 2.4826 | -9999 |
| 2 | None | 1.0 | 1.0 | 127.62043 | LINESTRING (636966.863 4518522.211, 636966.965... | 3 | fracture | 1 | 1 | 7.7849 | -9999 |
| 3 | None | 1.0 | 1.0 | 124.38020 | LINESTRING (636962.413 4518528.099, 636962.681... | 4 | fracture | 1 | 1 | 6.5703 | -9999 |
| 4 | None | 1.0 | 1.0 | 124.37587 | LINESTRING (636962.398 4518525.605, 636963.005... | 5 | fracture | 0 | 1 | 1.6035 | -9999 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1936 | None | 0.0 | 1.0 | 123.82891 | LINESTRING (637015.019 4518530.419, 637015.622... | 1937 | fracture | 0 | 1 | 1.4804 | -9999 |
| 1937 | None | 1.0 | 1.0 | 126.55001 | LINESTRING (637080.842 4518576.802, 637081.372... | 1938 | fracture | 0 | 1 | 1.0023 | -9999 |
| 1938 | None | 1.0 | 1.0 | 132.88082 | LINESTRING (637081.336 4518576.563, 637081.647... | 1939 | fracture | 0 | 1 | 2.4438 | -9999 |
| 1939 | None | 1.0 | 1.0 | 106.56774 | LINESTRING (637040.824 4518482.011, 637041.385... | 1940 | fracture | 0 | 1 | 5.4775 | -9999 |
| 1940 | None | 1.0 | 1.0 | 123.48189 | LINESTRING (637056.496 4518515.642, 637057.313... | 1941 | fracture | 0 | 1 | 5.9854 | -9999 |
1941 rows × 11 columns
NetworkFitter#
The network fitter class is responsible of running the statistical analysis on the fracture network. There are different options:
use_survival: Boolean flag to use survival (True) or treat the data as if there were no censoring (False). Default is True.
complete_only: Boolean flag to use only complete measurements (True) or all the dataset (False). This flag is used only when use_survival is False. Default is False.
use_AIC: Boolean flag to use AIC (true) or AICc (false) for model selection. Default is True
These options are useful to compare different ways of fitting the data with survival analysis however we strongly suggest to always use survival analysis since in case of no censoring the final results will be the same as the other methods.
[4]:
fitter = Statistics.NetworkFitter(fracture_net)
Fit different distributions#
All the rv_continous distribution present in scipy are valid (https://docs.scipy.org/doc/scipy/reference/stats.html#continuous-distributions).
Each time a fit is run the Akaike, Kolmogorov-Smirnov, Koziol and Green and Anderson Darling distances are calculated and saved.
[5]:
fitter.fit('lognorm')
fitter.fit('expon')
fitter.fit('norm')
fitter.fit('gengamma')
fitter.fit('powerlaw')
fitter.fit('weibull_min')
Fitting lognorm on data
Fitting expon on data
Fitting norm on data
Fitting gengamma on data
Fitting powerlaw on data
Fitting weibull_min on data
Show the model rank table#
[6]:
fitter.fit_records(sort_by='Akaike').iloc[:,:-1] # the iloc is to remove the last column that is not useful in this case
[6]:
| name | Akaike | delta_i | w_i | max_log_likelihood | KS_distance | KG_distance | AD_distance | Akaike_rank | KS_rank | KG_rank | AD_rank | Mean_rank | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | lognorm | 8522.146941 | 0.0 | 1.0 | -4259.07347 | 0.016002 | 0.072501 | 0.555217 | 1 | 1 | 1 | 1 | 1.00 |
| 1 | gengamma | 8553.929004 | 31.782064 | 0.0 | -4273.964502 | 0.025574 | 0.308545 | 2.62588 | 2 | 2 | 2 | 2 | 2.00 |
| 2 | weibull_min | 8770.365928 | 248.218987 | 0.0 | -4383.182964 | 0.057863 | 2.534663 | 19.183036 | 3 | 3 | 4 | 3 | 3.25 |
| 3 | expon | 8774.850744 | 252.703803 | 0.0 | -4386.425372 | 0.06293 | 2.327395 | 19.528382 | 4 | 4 | 3 | 4 | 3.75 |
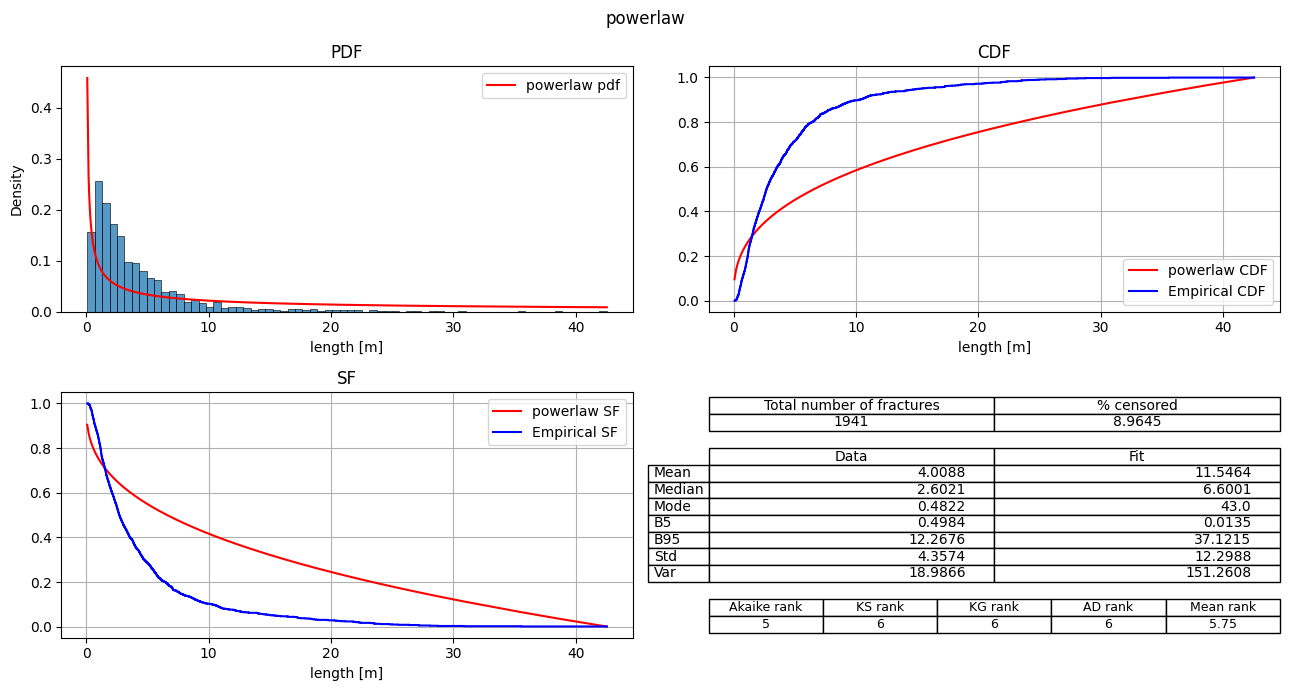
| 4 | powerlaw | 10639.543222 | 2117.396281 | 0.0 | -5317.771611 | 0.322579 | 71.711973 | 354.199529 | 5 | 6 | 6 | 6 | 5.75 |
| 5 | norm | 10682.113997 | 2159.967056 | 0.0 | -5339.056998 | 0.182519 | 24.538034 | 148.011215 | 6 | 5 | 5 | 5 | 5.25 |
Plot the different models using PITsummary plots#
[7]:
# Plot specific model
fitter.plot_PIT(fitter,position=[3],sort_by='Akaike')
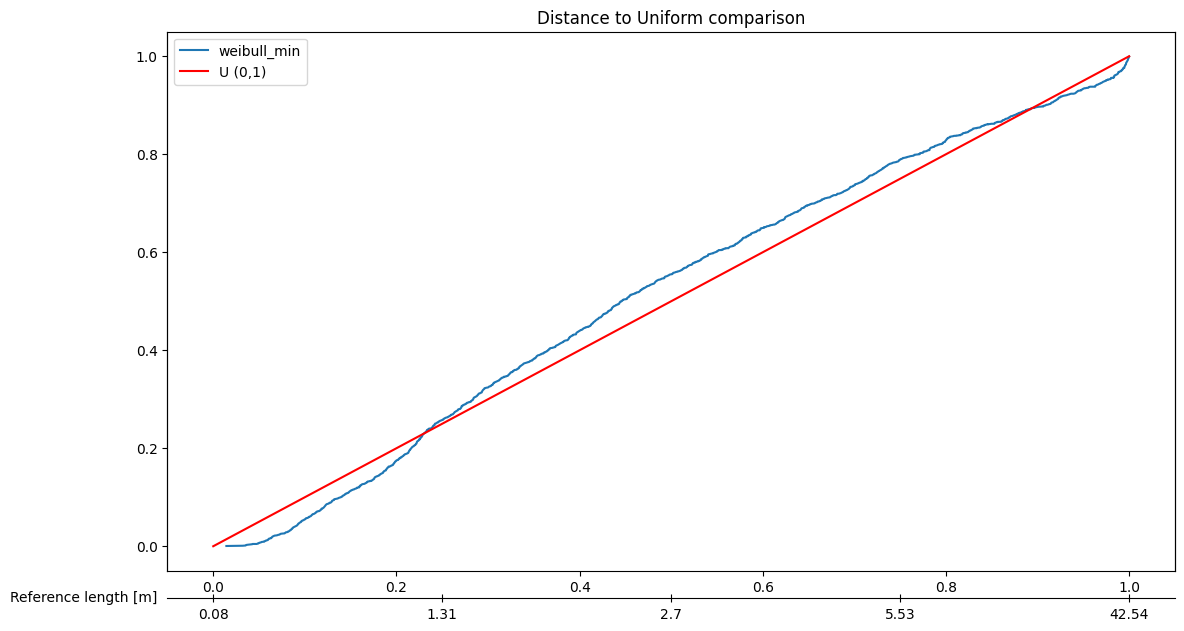
[8]:
# Plot specific models together
fitter.plot_PIT(fitter,position=[1,2,3],sort_by='Akaike', bw=True) # bw flag to make the plot color-blind friendly
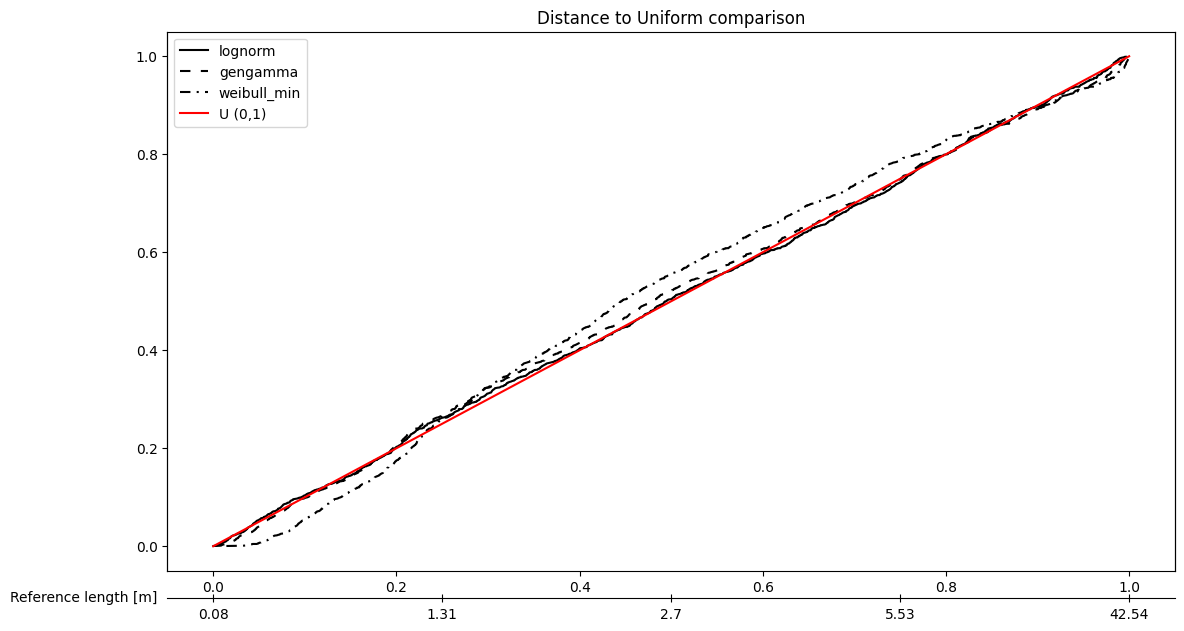
[9]:
# Plot all the models
fitter.plot_PIT(sort_by='Akaike', bw=True)
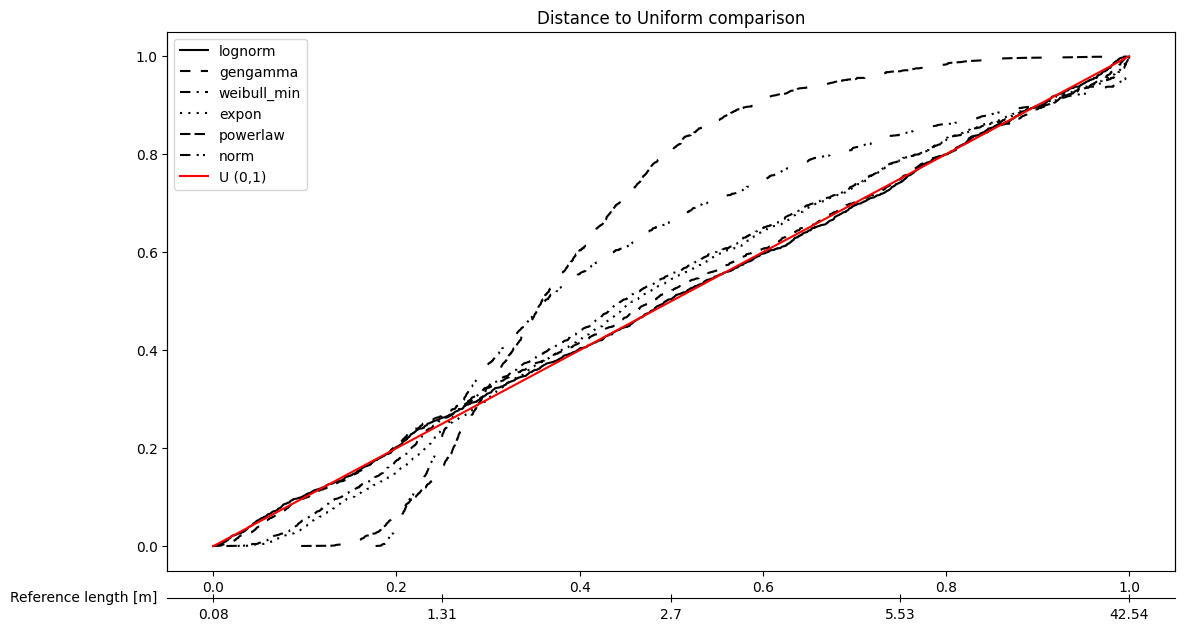
Plot summary plots#
[10]:
# Plot specific model
fitter.plot_summary(position=[1], sort_by='Mean_rank')
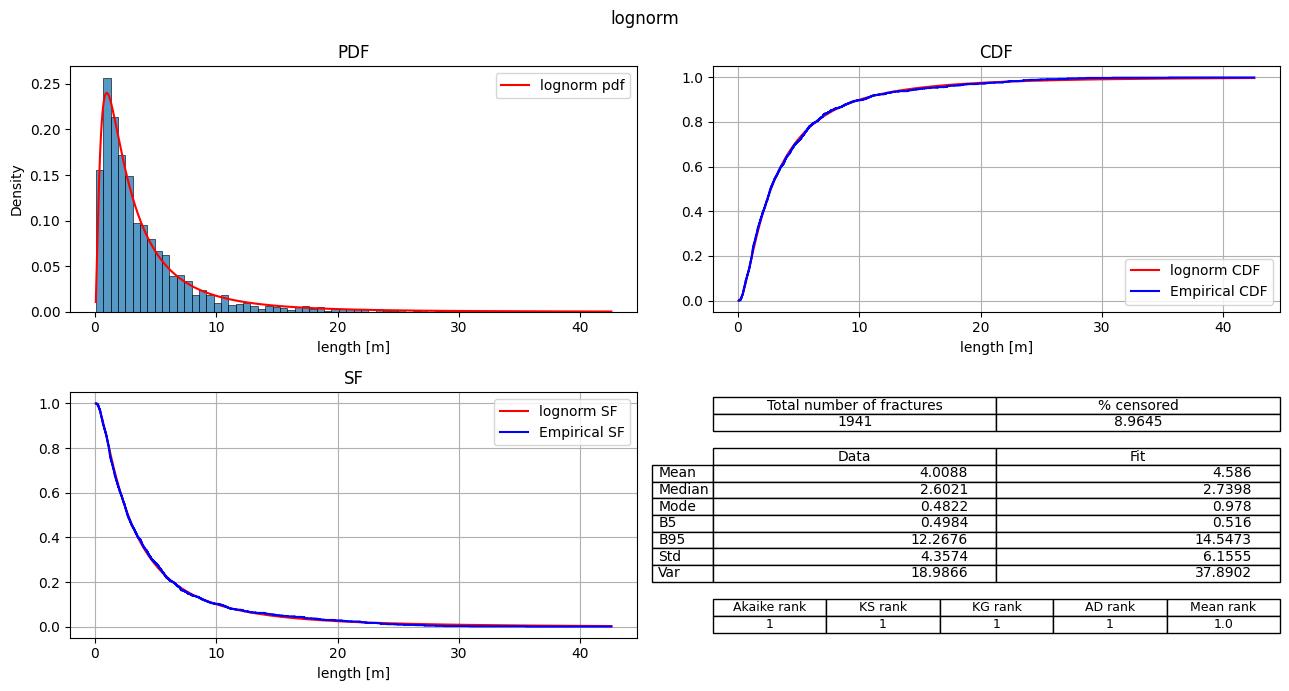
[11]:
# Plot specific models (separate plots)
fitter.plot_summary(position=[1,2,3], sort_by='Mean_rank')
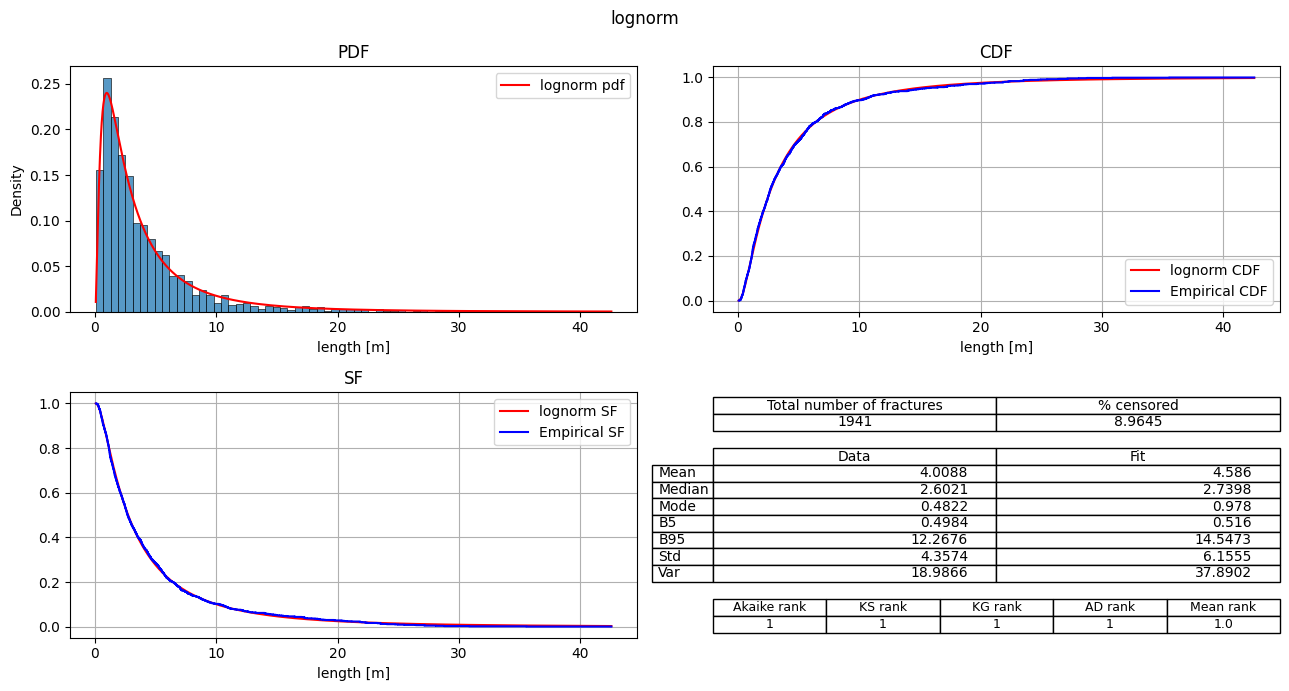
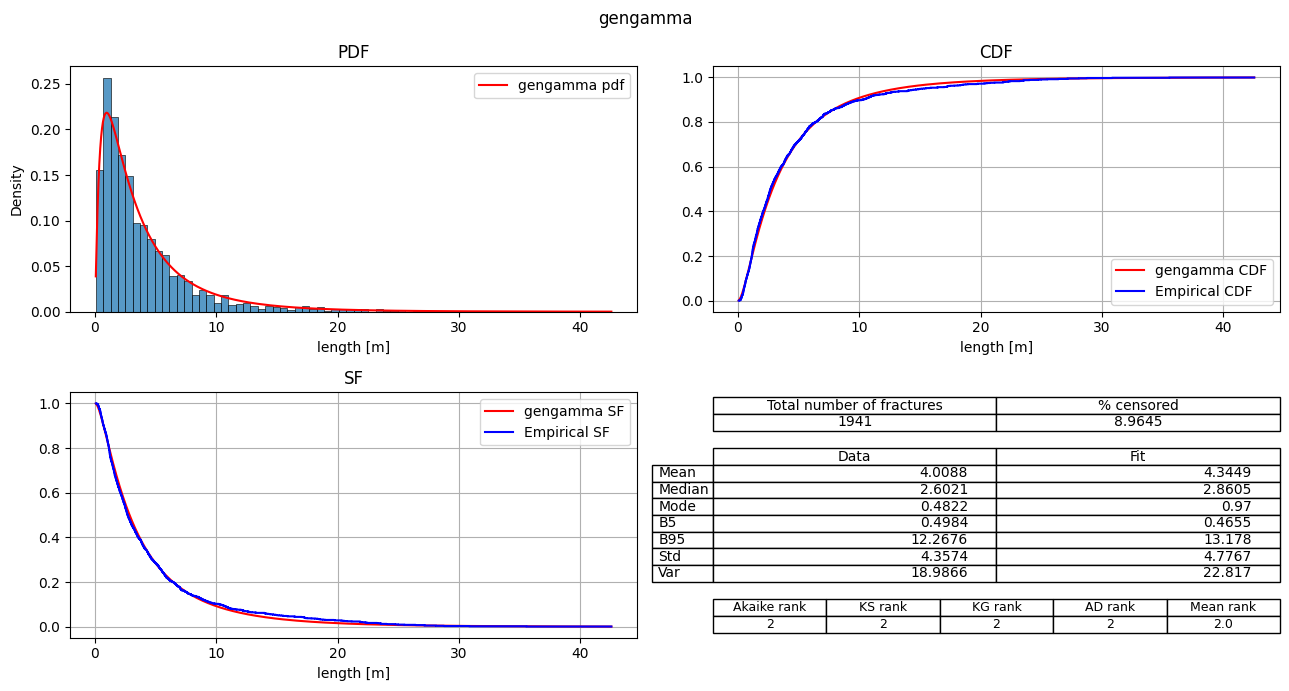
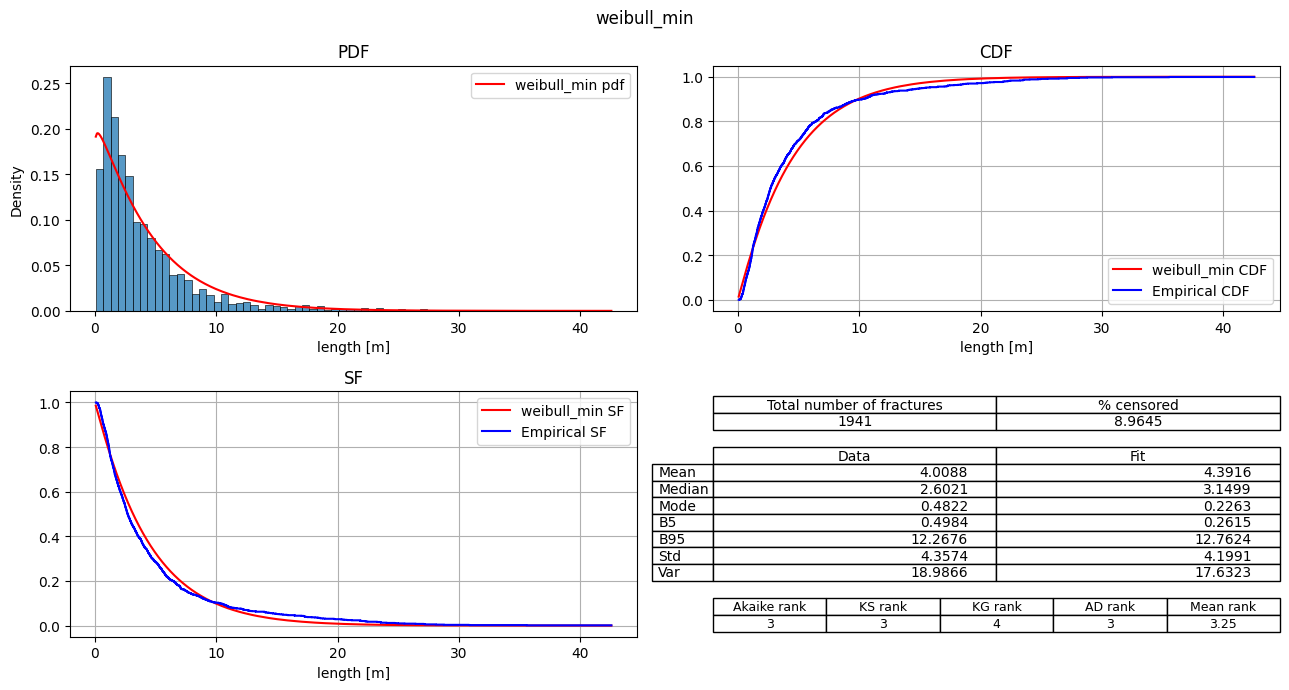
[12]:
# Plot all the models (separate plots)
fitter.plot_summary(sort_by='Mean_rank')
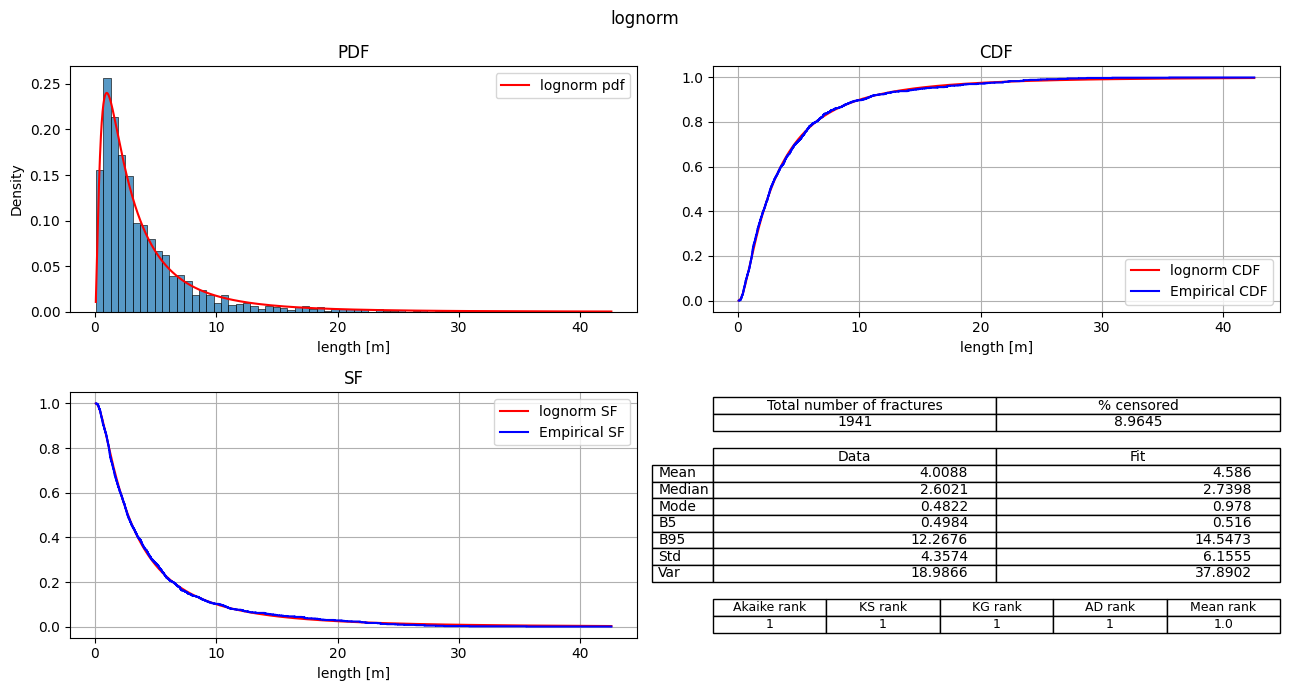
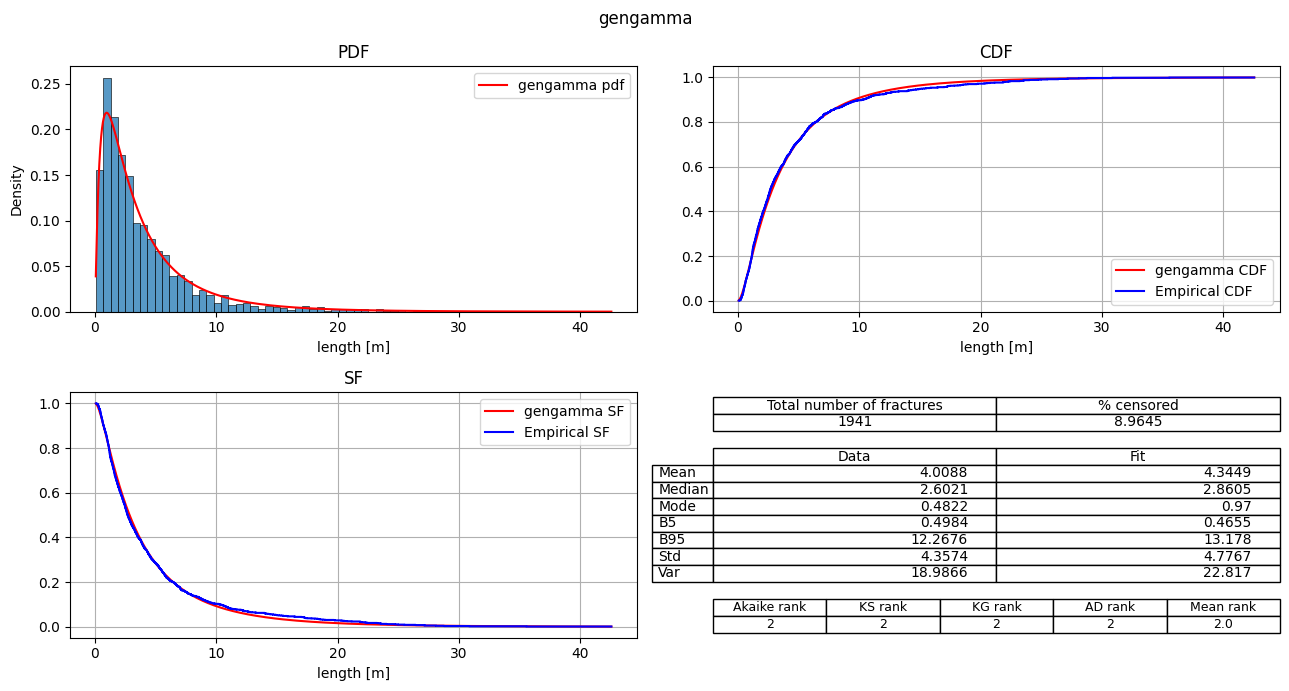
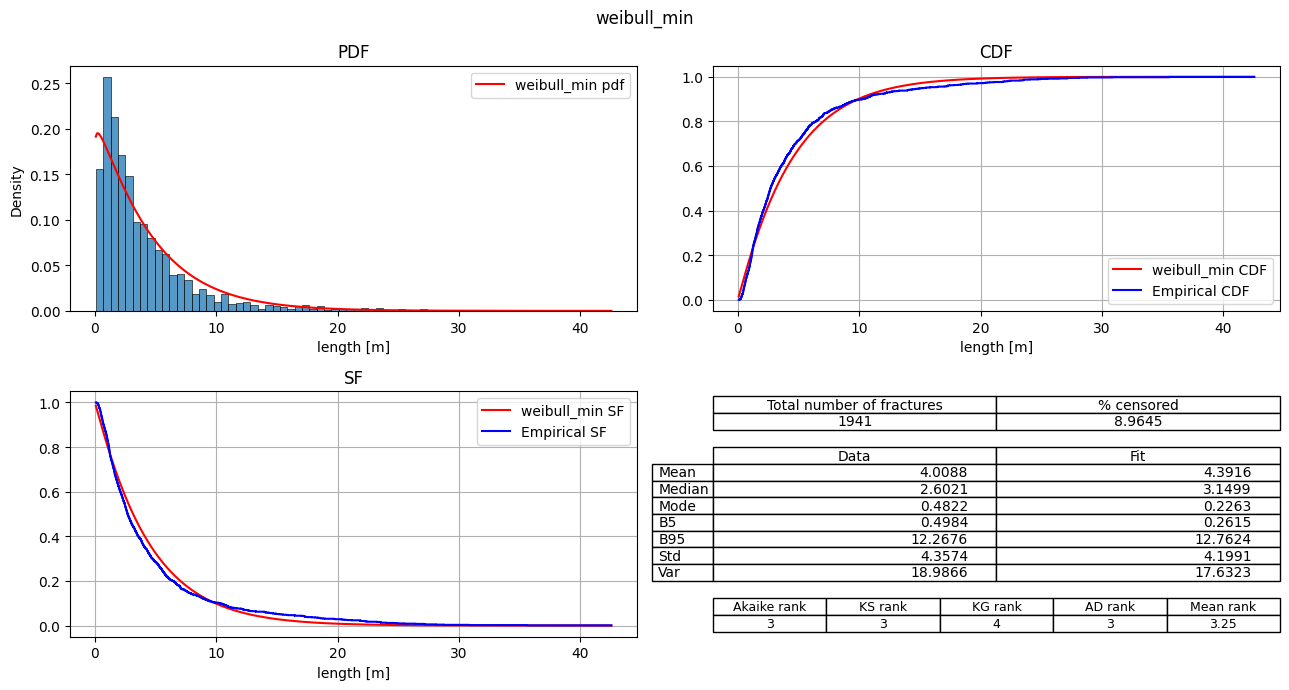
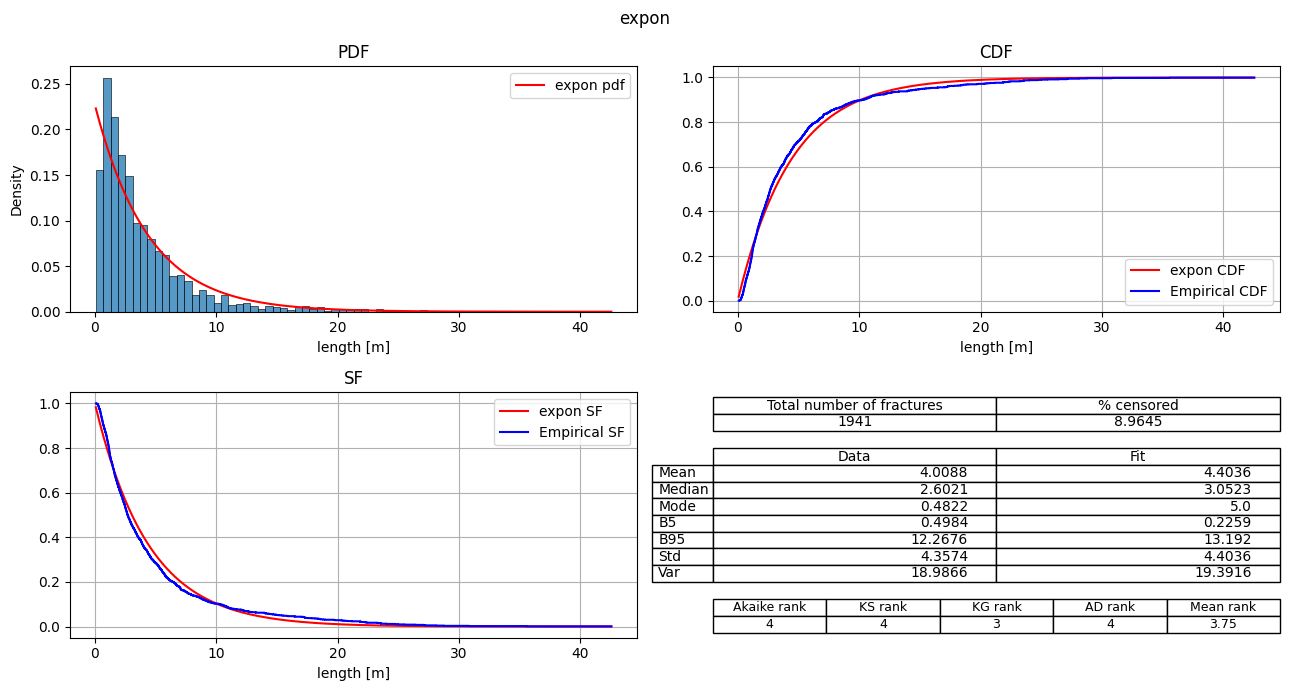
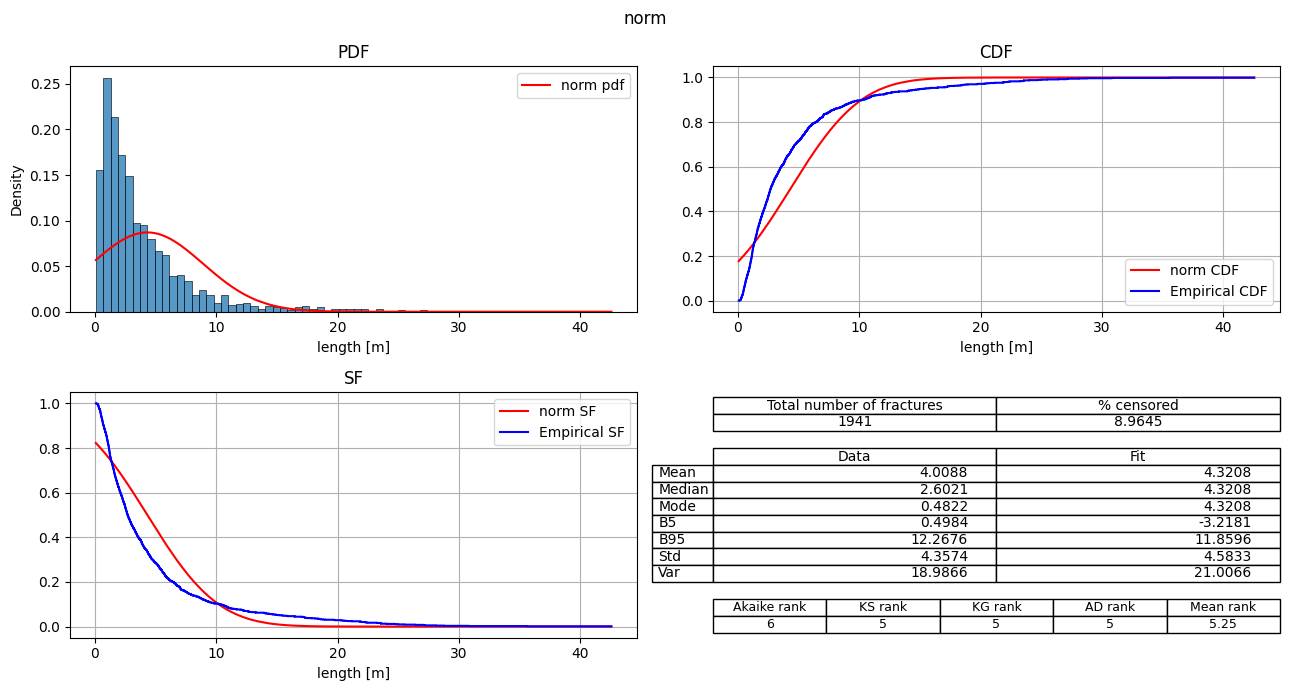
Export the fit_records table#
The fit_records table can also be saved as csv, excel or directly to clipboard in a excel friendly format
[ ]:
fitter.fit_result_to_csv('test_export.csv')
fitter.fit_result_to_excel('test_export.xlsx')
fitter.fit_result_to_clipboard()